AI-generated answers have recently become an important part of the purchase decision process. As a result, many teams are starting to ask how they can improve their brand's position within those answers. To improve anything, however, you first need a way to measure it — a baseline that shows whether things are actually moving in the right direction.
In practice, AI visibility is measured by analyzing how AI systems respond to predefined prompts.
We input questions or commands that a potential customer might realistically ask while having purchase intent, and then observe whether the AI mentions our brand in its response.
AI Visibility Metrics
In the context of AI visibility, several core metrics can be identified. Each of them can be further broken down into more granular sub-metrics:
- Brand mention rate — the percentage of prompts in which a specific brand appears at least once.
- Brand classification — whether the mention refers to our brand, a competitor, user-generated content, or an authority source
- Brand position — the order in which brands appear in lists; generally, earlier and more frequent mentions are more valuable. Position depends on response format: a ranked list gives a clear #1, #2, #3, while a paragraph may not.
- Practical position metrics — share of top-3 mentions, or average position when the model outputs a list
- Sentiment — how the brand is described or evaluated
- Source rate — the frequency with which a domain or source is cited in AI-generated responses. Citations depend on model, web-browsing mode, region, personalization, and whether the UI exposes citations at all.
- Citation order — the position of the source within the list of citations
- Intent/category coverage — the share of distinct intents or categories (e.g., “best for long runs”, “best value”, “best for beginners”) where the brand appears at least once.
- Intent presence — which intents or funnel stages include a mention of our brand
- Coverage by funnel stage — awareness vs consideration vs decision-stage prompts
Example (illustrative). For the prompt “Best running shoes for marathons?” run 30 times:
- Mention rate: 67%
- Average position when listed: 2.1
- Top-3 share: 80%
- Sentiment: mostly positive (qualitative)
- Top cited domains: runnersworld.com, reddit.com, wirecutter.com (illustrative only)
These metrics form the foundation for building trend charts over time and are most meaningful when analyzed as trends rather than as one-time snapshots. They allow teams to determine whether a brand's AI visibility is increasing, declining, or remaining stable.
Based on the same data, it is also possible to:
- build competitive rankings
- identify the most frequently cited sources, such as blog articles, forum threads, or other external content
Probabilistic Nature of LLM Responses
AI models are probabilistic by nature, which means individual responses can vary even when the same prompt is used. Because of this, single prompt executions are not sufficient to produce reliable results.
A single run may mention a brand, the next one may not, and another one may mention it again. Only by running the same prompts multiple times and analyzing a larger sample can we gain statistically meaningful confidence in the results.
A practical rule of thumb: run each prompt 20–50 times per model and analyze weekly trends rather than single-day snapshots. Treat changes as meaningful only if they stay stable over multiple days and across many prompts — short-lived spikes or dips often reflect random variation rather than real shifts in visibility.
Prompt Selection
Another critical aspect of AI visibility measurement is prompt selection. There is no publicly available data showing which exact questions users most frequently ask when, for example, searching for running shoes. To a large extent, prompt selection therefore involves educated guessing about how users phrase their queries in chat-based interfaces.
For this reason, it is important to work with a larger and more diverse set of prompts, such as:
- “What are the best running shoes?”
- “Which running shoes would you choose?”
Using different variations of similar questions helps reduce bias.
At the same time, prompts themselves have a direct impact on statistical outcomes. For example, if our brand is Nike and we use a prompt such as “Which running shoes should I choose: Nike or Adidas?”, we can reasonably expect only those two brands to appear in the response.
As a result, both brands will dominate visibility metrics compared to more general prompts like “Best running shoes?”, where many more brands are likely to be mentioned.
General prompt — “Best running shoes?”
Broader response with many brands in the competitive landscape.
Comparative prompt — “Which running shoes should I choose: Nike or Adidas?”
Narrow response limited to the two specified brands.
Analyzing both types of prompts together can therefore distort the results. It may incorrectly suggest that Adidas is the primary competitor, or that our brand's visibility is higher than it would be in a broader competitive context. For this reason, it is usually better to rely on more general prompts, while treating highly specific prompts separately.
Another important — but equally specific — category consists of direct brand-related prompts, such as “What do you think about running shoes from brand X?”. Combined with model memory and web search capabilities, these prompts help determine whether the model recognizes the brand at all and which sources are most frequently cited in relation to it.
It is reasonable to assume that users will eventually ask follow-up questions about specific brands or models during the decision-making process. However, these prompts also have important implications for how visibility is measured relative to competitors.
Prompt Groups
A practical approach is to isolate prompts into groups, each serving a distinct analytical purpose:
- General prompts — e.g. “Best running shoes?”
Used to understand the overall competitive landscape.
- Comparative prompts — e.g. “Which running shoes should I choose: Nike or Adidas?”
In this case, the order of brand mentions and sentiment become especially important. For example, comparing Nike with a non-specialist brand like Pierre Cardin in a running context should clearly reveal which option is actually being recommended.
- Brand-specific prompts — e.g. “What do you think about running shoes from brand X?”
Used to assess brand recognition by the LLM and identify the most frequently cited sources related to the brand.
Results should always be interpreted within the context of the prompt group they belong to, rather than aggregated across fundamentally different prompt types.
Manual vs Automated Tracking
At this point, we understand how AI visibility measurement works and which metrics should be tracked. The remaining question is how to execute this process in practice.
One option is to manually input prompts, analyze responses, enter results into spreadsheets, and create charts by hand. While this approach is possible, it quickly becomes time-consuming and difficult to scale.
This is where automated tools become useful. One such tool is Genwolf, built for SEO, content, and product marketing teams who want to track AI visibility the way they track SEO rankings. It lets you define relevant prompt sets and run them automatically on a recurring basis (for example, once per day). The platform collects responses, analyzes them, classifies brands, counts occurrences, generates trend charts, and highlights the most frequently cited sources.
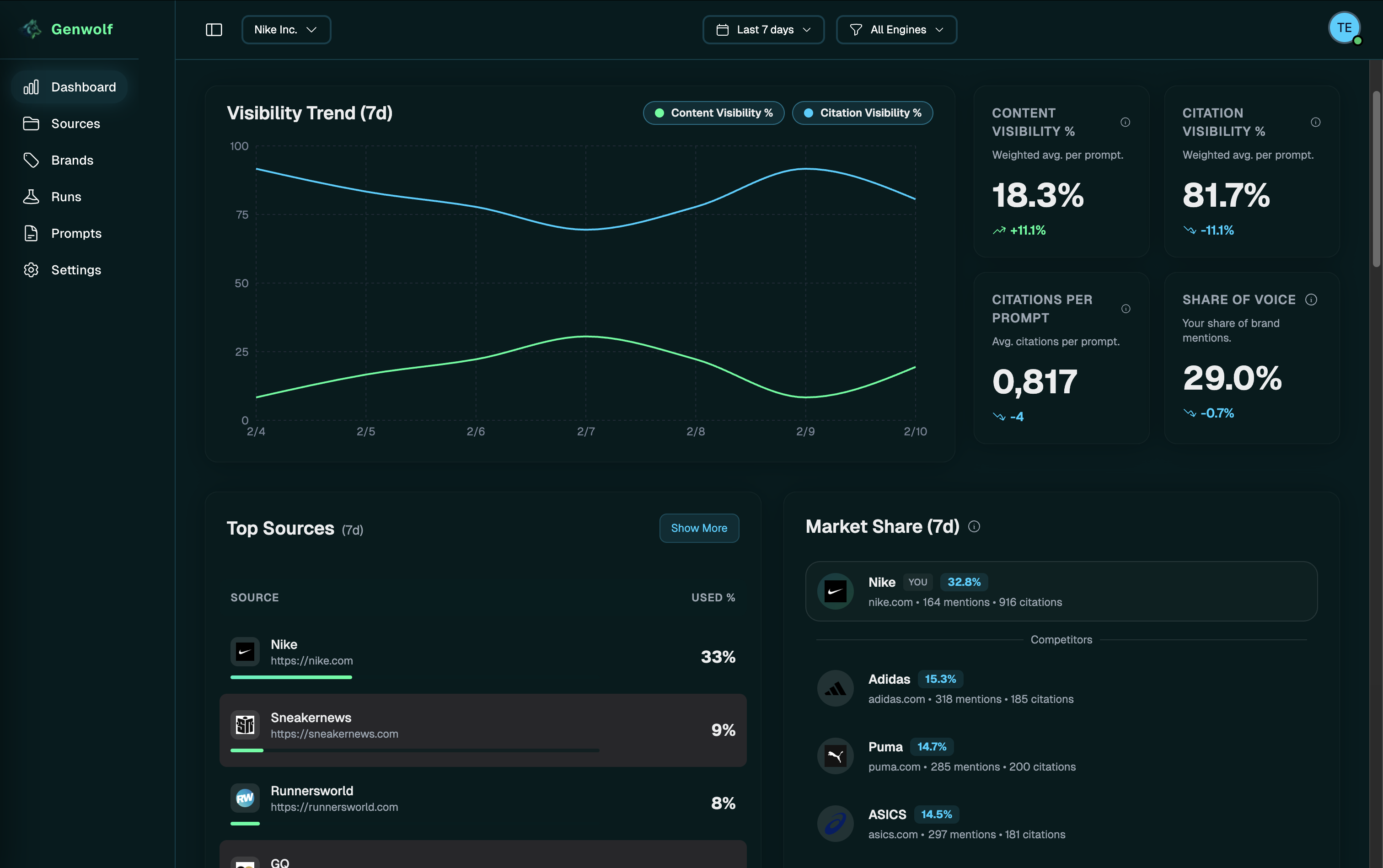
If you want, you can try Genwolf with a 7-day free trial.
Summary
- AI visibility cannot be measured with a single prompt or a one-time check — AI responses are probabilistic and vary across runs.
- Reliable AI visibility measurement requires running the same prompts multiple times and analyzing results as trends over time.
- The most important AI visibility metrics include brand mention rate, source citation rate, intent/category coverage, and sentiment.
- Prompt selection has a direct impact on visibility statistics and can significantly distort results if different prompt types are mixed together.
- Structured tracking — whether manual or automated — is essential for understanding how often, where, and in what context a brand appears in AI-generated answers.
